当整个具身智能行业都在追逐VLA(视觉-语言-动作)模型时,一家名为橡木果(Acorn Robot)的清华背景团队却选择了一条截然不同的路。他们放弃了让机器人「用眼睛看、用脑子想」的主流范式,转而从底层构建「具身本能」,让机器人在完全没有对应训练的情况下,就能稳稳拿住物体、与人博弈。这种自下而上的技术路线,正在为具身智能的工业落地打开一扇新的大门。
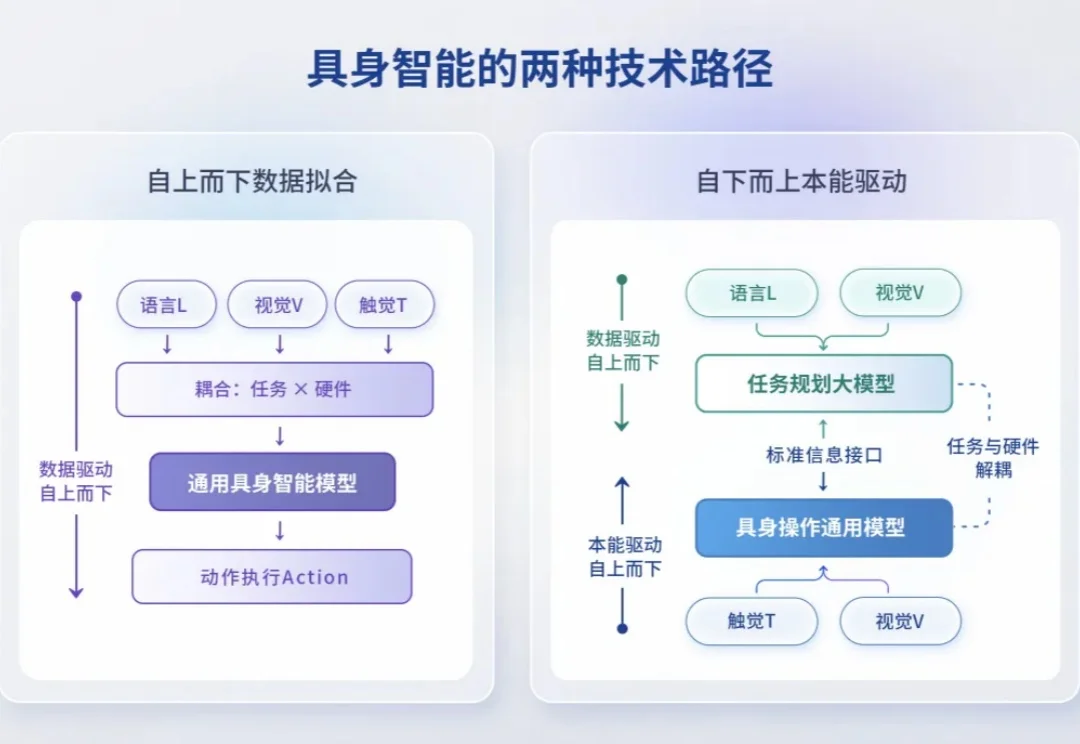
VLA模型的底层逻辑是模仿学习,通过海量数据训练机器人拟合人类动作。但这一路线在真实工业场景中正遭遇瓶颈。物理交互中的手感、力矩变化、摩擦反馈等触觉信息,无法通过仿真环境完全模拟。即使在工厂里,外观相同的两个夹爪因导轨松紧不同,也需要不同的模型参数。更关键的是,VLA依赖的单一视觉维度无法感知重心偏移、滑移趋势等触觉信息,导致「眼睛学会了,上手却不行」。当前业界已出现VLA向VTLA演进的趋势,新增的触觉维度正是为了应对精细物理交互的挑战。
橡木果的解法是彻底重构技术架构。他们将任务规划(大脑)与操作执行(小脑)解耦,专注于攻克底层的操作执行层。其核心是端侧自主决策模型Natus,完全嵌入灵巧手等末端执行器中,由「触觉刺激的本能反射」与「自主学习的肌肉记忆」构建。该模型包含三大类本能:定向本能指引末端向目标移动,探索本能自动沿物体表面寻找稳定接触构型,执行本能则以「滑移最小化」或「阻抗匹配」为目标,实时调节电机电流。所有调控均来自触觉信息的实时反馈,频率高达200Hz,无需任何训练数据。
在测试中,机器人从未见过卡片型物体,却能通过自主探索把卡片翘起一角成功抓取;面对半瓶水的饮料,它会反复试探重心逐步调整。这种「本能驱动」的方式,正在打破VLA在工业场景中的数据依赖和泛化难题。未来,具身智能的商用化或许不再需要为每个工位单独适配模型,而是让机器人像人类一样,通过本能适应物理世界的复杂性。对于从业者而言,这一路线提醒我们:在追逐大模型的同时,不要忘记触觉这个被长期忽略的维度,它可能是连接AI与物理世界的关键钥匙。