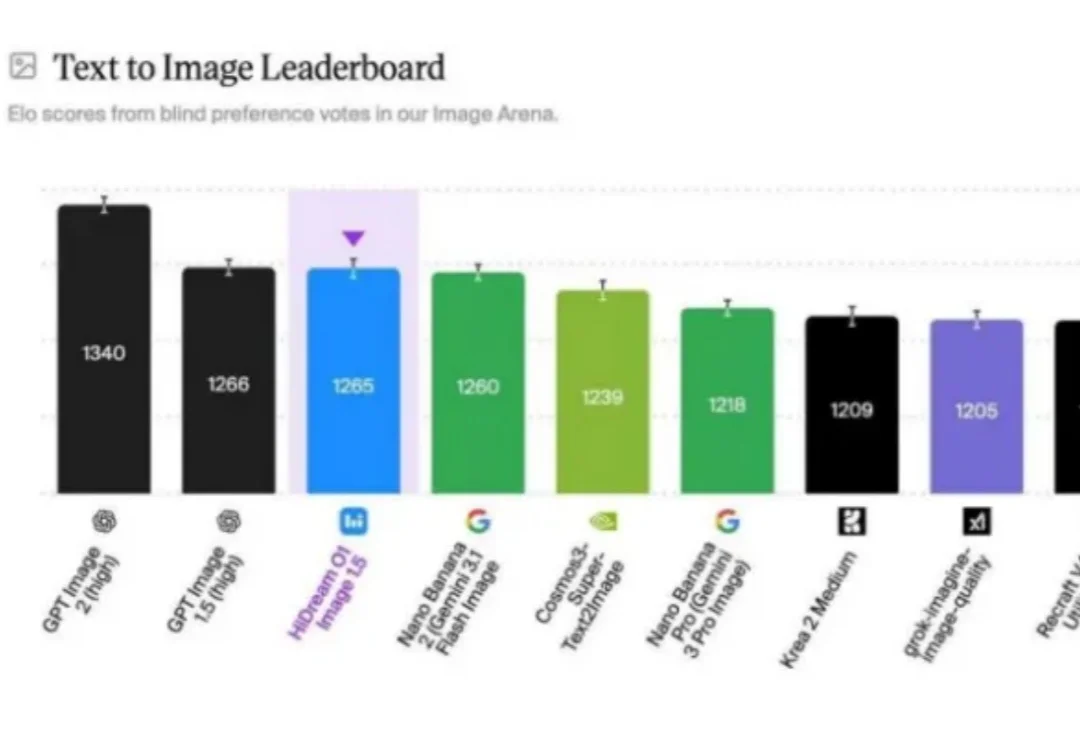
大模型竞赛进入2026年,当行业普遍将AI视为参数规模与算力堆砌的无限游戏时,一家成立仅三年多的中国创业公司——智象未来(HiDream.ai),在图像生成赛道掀了桌子。短短半月内,其商用模型HiDream-O1-Image-1.5与开源模型HiDream-O1-Image-Dev-2604先后登顶全球权威评测平台Artificial Analysis的文生图榜单,分别拿下中国第一、全球第二和开源模型全球第一的成绩,超越了Google的Nano Banana 2、NVIDIA的Cosmos3-Super-Text2Image以及字节跳动的Seedream 4.0等国内外大厂的主流模型。这不是一次偶发的技术爆发,而是底层架构创新的必然结果。榜单采用匿名对比、用户投票和ELO动态排名机制,在超过4000个样本的对比中,HiDream-O1-Image-1.5取得1265 ELO评分,这反映了模型在图像质量、语义遵循、复杂画面生成和文字渲染等综合能力上的显著提升。在算力、数据和生态禀赋都不占优的背景下,智象未来选择了一条截然不同的技术路径——像素级原生全模态架构UiT。当前主流文生图模型普遍沿用“文本编码器+VAE+扩散Transformer”的模块化架构,信息在多个模块间转换时容易造成细节丢失和语义偏差。而UiT架构将图像像素、文本Token、视频体素等原始信号统一映射至同一个共享表征空间,从模型底层实现了全模态信息的理解与生成,彻底消除了模态转换带来的损耗。这一技术路线并非凭空而来。智象未来核心团队专注AIGC领域超过10年,由院士领衔,是国内少有的兼具前沿算法、工程系统与真实业务场景完整闭环的团队。早在2017年,团队便提出了全球最早的视频生成模型论文之一TGANs-C,并深度参与过全球第二大视频搜索引擎和中国最大自营电商平台图片搜索引擎的建设,还将多模态技术落地到物流具身智能、千卡级准实时智能视频推理等高复杂度产业场景。这种从研究到落地的全链条经验,让团队敢于放弃成熟路线,选择一条更难但更具想象力的路。半月两次问鼎全球,意味着中国AI创业公司完全有机会在图像生成这个巨头环伺的赛道中突围。对于AI从业者和爱好者而言,智象未来的案例提供了一个重要启示:在技术范式转换的窗口期,架构创新比堆砌参数更能撬动格局。随着UiT架构的持续迭代和开源生态的完善,我们有理由期待更多中国团队在底层技术上实现突破。对于关注AI图像生成领域的朋友,不妨亲自体验一下HiDream-O1系列模型,感受一下原生全模态架构带来的生成质量提升。